from BPTK_Py import Model
from BPTK_Py import sd_functions as sdMake Your PSF Grow (Part 2)
Building a Model To Analyse Game Strategies
Please make sure to read part one of this document - it introduces a challenge which we “solve” with the model presented in this document.
How did you perform? Did you manage to solve the puzzle? By trial and error or did you have a clear strategy?
Let’s see how we can approach this problem systematically using our business prototyping toolkit - in particular, let’s build a small simulation model to help us analyse the PSF and devise some strategies to reach the game targets.
I like to build my models in small steps, testing intermediate stages as I go along. That makes it much easier to find mistakes (which inevitably happen) as you go along. I’m going to build the model using the SD DSL which is part of the BPTK framework.
Once I’ve “finished” a model, I then extract it into separate Python files, which are easier to maintain in the long run and can be referenced from multiple notebooks. You can find the extracted model in the src directory.
The diagram below shows the overall module structure we are working towards.

This repository also contains a version of the model build using Stella Architect from isee systems, i.e. in the XMILE format. If you are more interested in the XMILE variant please follow the notebooks in the
xmilefolder. From an SD perspective, both model variants are identical and produce identical results.
Step 1: Cash
It’s easiest to start with cash and cash flow, because these are clearly defined concepts that leave little open to discussion. They are also straightforward to model in System Dynamics.
By definition, cash flow is simply the difference between the revenue we collect and the cost we incur. The stock and flow diagram shown below captures this nicely.

model = Model(starttime=0.0,stoptime=24.0,dt=1.0,name='MakeYourPsfGrow')cash = model.stock("cash")
cashIn = model.flow("cashIn")
cashOut= model.flow("cashOut")
collectingRevenue = model.converter("collectingRevue")
cost = model.converter("cost")
cashFlow = model.converter("cashFlow")Now let’s quantify the model. Given assumption #14 we know that 160 professional staff are assigned to project delivery, and given assumption #6 we know they turn over EUR 17.6k per month each. Assumption #7 tells us that we bill project work on a monthly basis.
The cost is the monthly salary (80k/12) plus EUR1k workplace cost and the overhead cost of EUR 306k (assumptions #9, #10, #11). Thanks to assumption #13, we also know the initial cash level is at EUR 1000k.
So we can define the following values:
cash.initial_value=1000.0
collectingRevenue.equation=160.0*17.6
cashIn.equation=collectingRevenue
cost.equation=200.0*(80/12+1)+306.0
cashOut.equation = cost
cashFlow.equation = cashIn -cashOutNote that I clearly separated the cashIn and cashOut flows from the cost and collecting revenue converters. I could have added the numbers directly into the flow (e.g. setting cashIn = collectingRevenue instead of cashIn = collectingRevenue = 160 * 17.600). The reason I did this is that I like to keep my simulation logic out of the flows as far as possible - this makes the model visually more explicit and also makes it easier to refactor the model (e.g. moving logic around between diagrams).
We ought to check that the model works as expected: the cash flow should be constant and equal to cashFlow = 160 * 17.6 - 200 * (80/12 + 1) - 306 = 976.67. This also means that after 24 months we should have cash = 1000 + 24 * 922.67 = 24440.08.
I’ve plotted and tabulated the values below, as you can see the numbers are as expected.
import BPTK_Py
bptk = BPTK_Py.bptk()
bptk.register_scenario_manager(
{
"psfLocal":{
"model": model
}
}
)bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step1":{}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step1"],
equations=["cashFlow"],
title="Cash Flow",
x_label="Months",
y_label="€",
series_names={'cashFlow':'Step 1'}
)
We cast the values of the column “Time” from float to int.
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step1"],
equations=["cashFlow"],
title="Cash Flow Base Case",
x_label="Months",
y_label="€",
series_names={'cashFlow':'Cash Flow'},
return_df=True
)| Cash Flow | |
|---|---|
| t | |
| 0.0 | 976.666667 |
| 1.0 | 976.666667 |
| 2.0 | 976.666667 |
| 3.0 | 976.666667 |
| 4.0 | 976.666667 |
| 5.0 | 976.666667 |
| 6.0 | 976.666667 |
| 7.0 | 976.666667 |
| 8.0 | 976.666667 |
| 9.0 | 976.666667 |
| 10.0 | 976.666667 |
| 11.0 | 976.666667 |
| 12.0 | 976.666667 |
| 13.0 | 976.666667 |
| 14.0 | 976.666667 |
| 15.0 | 976.666667 |
| 16.0 | 976.666667 |
| 17.0 | 976.666667 |
| 18.0 | 976.666667 |
| 19.0 | 976.666667 |
| 20.0 | 976.666667 |
| 21.0 | 976.666667 |
| 22.0 | 976.666667 |
| 23.0 | 976.666667 |
| 24.0 | 976.666667 |
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step1"],
equations=["cash"],
title="Cash",
x_label="Months",
y_label="€",
series_names={'cash':'Step 1'}
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step1"],
equations=["cash"],
series_names={'cash':'Cash'},
return_df=True
)| Cash | |
|---|---|
| t | |
| 0.0 | 1000.0 |
| 1.0 | 1000.0 |
| 2.0 | 1000.0 |
| 3.0 | 1000.0 |
| 4.0 | 1000.0 |
| 5.0 | 1000.0 |
| 6.0 | 1000.0 |
| 7.0 | 1000.0 |
| 8.0 | 1000.0 |
| 9.0 | 1000.0 |
| 10.0 | 1000.0 |
| 11.0 | 1000.0 |
| 12.0 | 1000.0 |
| 13.0 | 1000.0 |
| 14.0 | 1000.0 |
| 15.0 | 1000.0 |
| 16.0 | 1000.0 |
| 17.0 | 1000.0 |
| 18.0 | 1000.0 |
| 19.0 | 1000.0 |
| 20.0 | 1000.0 |
| 21.0 | 1000.0 |
| 22.0 | 1000.0 |
| 23.0 | 1000.0 |
| 24.0 | 1000.0 |
Step 2: Making Cost Explicit
Another good model building practice is to explicitly model the constants: there should be now “magic” values that are not explicitly named, these are difficult to interpret for anyone reading the model (including yourself should you come back to the model at some future time).
So instead of setting
cost = 200 * (80/12 + 1) + 306
we should explicitly define a stock or converter for each number. That makes the model much more readable, makes each equation simpler to read, understand and correct.
This leads to the new diagram below.

professionalStaff = model.stock("professionalStaff")
staffSalary = model.converter("staffSalary")
workplaceCost = model.converter("workplaceCost")
staffCost = model.converter("staffCost")
overheadCost = model.converter("overheadCost")workplaceCost.equation=1.0
staffSalary.equation = 80.0/12
staffCost.equation = professionalStaff*(workplaceCost+staffSalary)
cost.equation=staffCost+overheadCostI’ve modeled the professional service staff as a stock (and not as a converter), because the number of staff the firm has on a given day cannot be calculated instantaneously from other numbers but will depend on the number of staff the firm had at the beginning of the simulation (200 in this case) plus the new staff that has been hired since then (we’ll model the hiring process itself in a later step).
professionalStaff.initial_value=200.0Because we have only reorganized the model without adding any new logic, we expect nothing to have changed. Nevertheless we should check that this is true.
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step2":{}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step2"],
equations=["cashFlow"],
title="Cash Flow",
x_label="Months",
y_label="€",
series_names={'cashFlow':'Step 2'}
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step2"],
equations=["cashFlow"],
series_names={'cashFlow':'Cash Flow'},
return_df=True
)| Cash Flow | |
|---|---|
| t | |
| 0.0 | 1282.666667 |
| 1.0 | 1282.666667 |
| 2.0 | 1282.666667 |
| 3.0 | 1282.666667 |
| 4.0 | 1282.666667 |
| 5.0 | 1282.666667 |
| 6.0 | 1282.666667 |
| 7.0 | 1282.666667 |
| 8.0 | 1282.666667 |
| 9.0 | 1282.666667 |
| 10.0 | 1282.666667 |
| 11.0 | 1282.666667 |
| 12.0 | 1282.666667 |
| 13.0 | 1282.666667 |
| 14.0 | 1282.666667 |
| 15.0 | 1282.666667 |
| 16.0 | 1282.666667 |
| 17.0 | 1282.666667 |
| 18.0 | 1282.666667 |
| 19.0 | 1282.666667 |
| 20.0 | 1282.666667 |
| 21.0 | 1282.666667 |
| 22.0 | 1282.666667 |
| 23.0 | 1282.666667 |
| 24.0 | 1282.666667 |
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step2"],
equations=["cash"],
title="Cash",
x_label="Months",
y_label="€",
series_names={'cash':'Step 2'}
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step2"],
equations=["cash"],
series_names={'cash':'Cash'},
return_df=True
)| Cash | |
|---|---|
| t | |
| 0.0 | 1000.0 |
| 1.0 | 1000.0 |
| 2.0 | 1000.0 |
| 3.0 | 1000.0 |
| 4.0 | 1000.0 |
| 5.0 | 1000.0 |
| 6.0 | 1000.0 |
| 7.0 | 1000.0 |
| 8.0 | 1000.0 |
| 9.0 | 1000.0 |
| 10.0 | 1000.0 |
| 11.0 | 1000.0 |
| 12.0 | 1000.0 |
| 13.0 | 1000.0 |
| 14.0 | 1000.0 |
| 15.0 | 1000.0 |
| 16.0 | 1000.0 |
| 17.0 | 1000.0 |
| 18.0 | 1000.0 |
| 19.0 | 1000.0 |
| 20.0 | 1000.0 |
| 21.0 | 1000.0 |
| 22.0 | 1000.0 |
| 23.0 | 1000.0 |
| 24.0 | 1000.0 |
Step 3: Modeling Receivables
Now that we have modelled the cost side, we should take a look at the income side. It is important to distinguish between making revenue and actually collecting it, because the PSF has to finance the period in between out of its cash - this can be particularly difficult during growth periods, because the new staff’s wages have to be paid before the revenue they are making actually arrives in the PSF’s bank account.
According to game assumption #8 there is an average collection time of 2 months. Hence we can model the collection process as a stock of receivables - the inflow is determined by the monthly revenue, the outflow is simply the inflow delayed by the collection time.

receivables = model.stock("receivables")
makingRevenue = model.flow("makingRevenue")
collectingRevenue = model.flow("collectingRevenue")
collectionTime = model.converter("collectionTime")
revenue = model.converter("revenue")
projectDeliveryFee = model.converter("projectDeliveryFee")
projectDeliveryRate = model.converter("projectDeliveryRate")The revenue is simply the monthly project delivery fee time the delivery rate. Given our assumptions about staff allocation (#8), the delivery rate is initially at 160 project months/month.
receivables.initial_value = 160*17.6*2
receivables.equation = makingRevenue-collectingRevenue
projectDeliveryFee.equation = 17.6
projectDeliveryRate.equation = 160.0
revenue.equation = projectDeliveryFee*projectDeliveryRate
makingRevenue.equation = revenueCollecting revenue takes 2 months, we model this using a delay function:
collectionTime.equation=2.0
collectingRevenue.equation=sd.delay(model,makingRevenue,collectionTime,160*17.6)With this model and these concrete values, we expect the receivables to be constant at collection time * revenue, which is 2 * 17.6 * 160 = 5632, and we expect both makingRevenue and collectingRevenue to be constant and equal to revenue, which is 17.6 * 160 = 2816.
The table below shows the model is behaving correctly.
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step3":{}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=["step3"],
equations=["receivables","makingRevenue","collectingRevenue"],
return_df=True,
series_names={
"mypsfg_step3_receivables":"Receivables",
"mypsfg_step3_makingRevenue":"Making Revenue",
"mypsfg_step3_collectingRevenue":"Collecting Revenue",
}
)| receivables | makingRevenue | collectingRevenue | |
|---|---|---|---|
| t | |||
| 0.0 | 5632.0 | 2816.0 | 2816.0 |
| 1.0 | 5632.0 | 2816.0 | 2816.0 |
| 2.0 | 5632.0 | 2816.0 | 2816.0 |
| 3.0 | 5632.0 | 2816.0 | 2816.0 |
| 4.0 | 5632.0 | 2816.0 | 2816.0 |
| 5.0 | 5632.0 | 2816.0 | 2816.0 |
| 6.0 | 5632.0 | 2816.0 | 2816.0 |
| 7.0 | 5632.0 | 2816.0 | 2816.0 |
| 8.0 | 5632.0 | 2816.0 | 2816.0 |
| 9.0 | 5632.0 | 2816.0 | 2816.0 |
| 10.0 | 5632.0 | 2816.0 | 2816.0 |
| 11.0 | 5632.0 | 2816.0 | 2816.0 |
| 12.0 | 5632.0 | 2816.0 | 2816.0 |
| 13.0 | 5632.0 | 2816.0 | 2816.0 |
| 14.0 | 5632.0 | 2816.0 | 2816.0 |
| 15.0 | 5632.0 | 2816.0 | 2816.0 |
| 16.0 | 5632.0 | 2816.0 | 2816.0 |
| 17.0 | 5632.0 | 2816.0 | 2816.0 |
| 18.0 | 5632.0 | 2816.0 | 2816.0 |
| 19.0 | 5632.0 | 2816.0 | 2816.0 |
| 20.0 | 5632.0 | 2816.0 | 2816.0 |
| 21.0 | 5632.0 | 2816.0 | 2816.0 |
| 22.0 | 5632.0 | 2816.0 | 2816.0 |
| 23.0 | 5632.0 | 2816.0 | 2816.0 |
| 24.0 | 5632.0 | 2816.0 | 2816.0 |
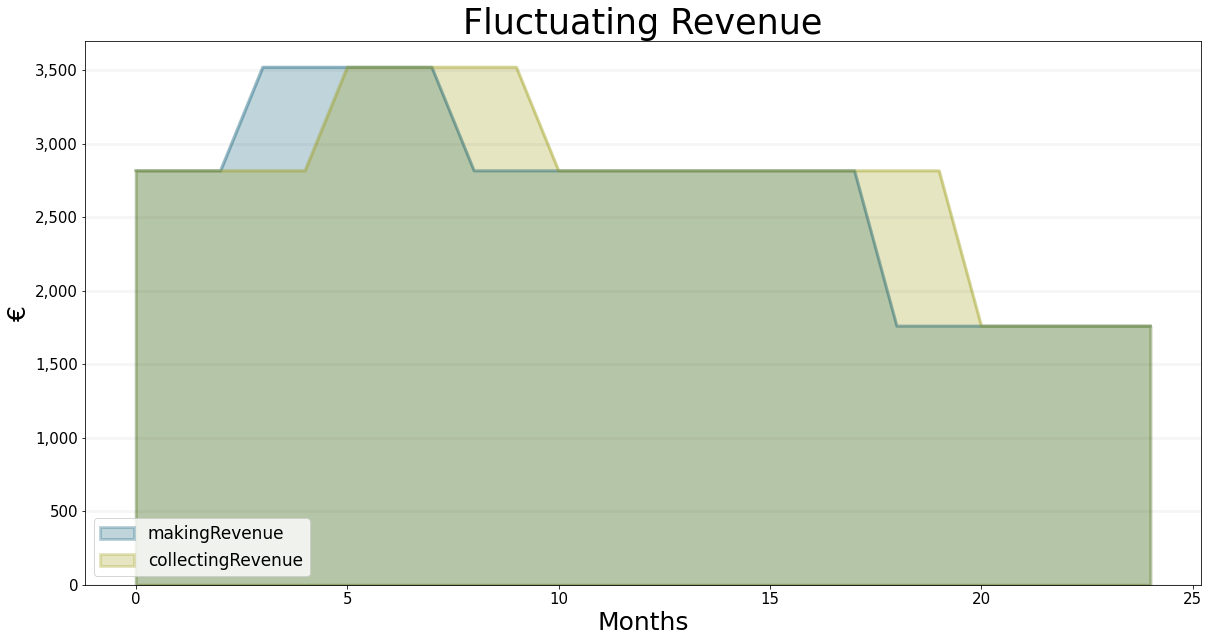
Unfortunately, because everything is constant, it is difficult to see whether our model of the receivables is working correctly. So we ought to test our model with some fluctuating revenue, to see whether the revenue collection is delaying properly - note that this is purely a test, the values we used for collecting revenue have nothing to do with game assumptions.
The graph below shows are model is behaving nicely, the shape of collectingRevenue is identical to that of makingRevenue, the entire graph is shifted by two months (i.e. the collection time)
projectDeliveryRate.equation=sd.lookup(sd.time(),"fluctuatingRevenue")bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step3":{
"points":{
"fluctuatingRevenue":[(0, 160), (1, 160), (2, 160), (3, 200), (4, 200), (5, 200), (6,
200), (7, 200), (8, 160), (9, 160), (10, 160), (11, 160), (12,
160), (13, 160), (14, 160), (15, 160), (16, 160), (17, 160), (18,
100), (19, 100), (20, 100), (21, 100), (22, 100), (23, 100), (24,
100)]
}
}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step3'],
equations=["makingRevenue","collectingRevenue"],
title="Fluctuating Revenue",
x_label="Months",
y_label="€"
)
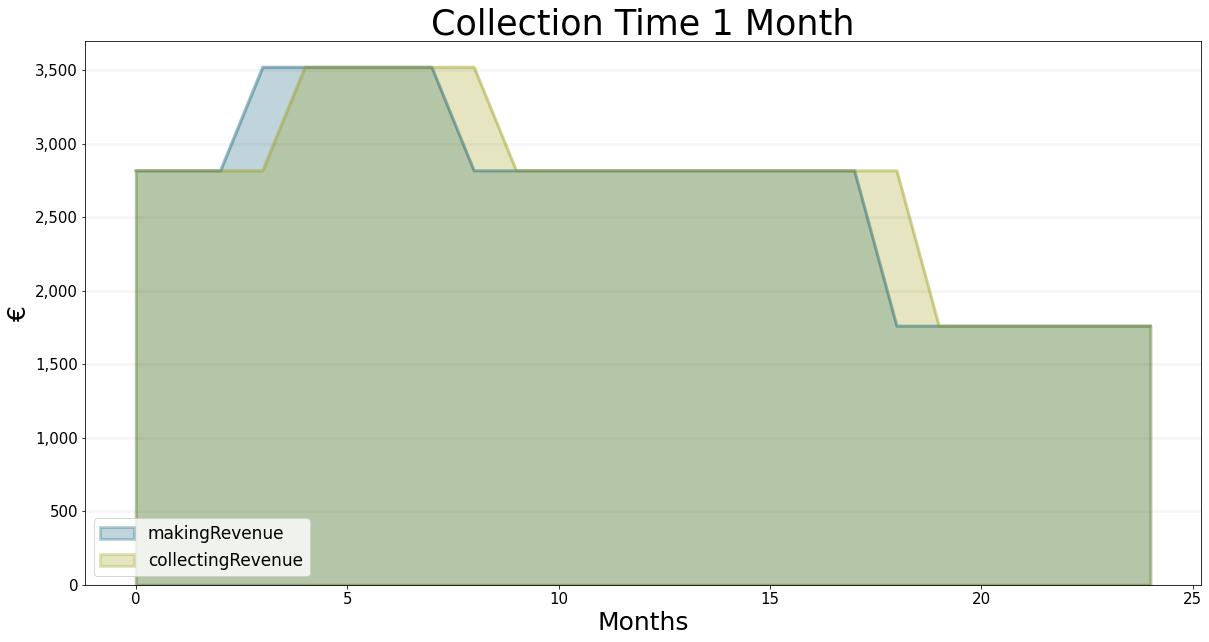
To illustrate this better, here is another scenario with the collecting time set to 1 month instead of two, but the same monthly revenue.
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step3_collectionTime1":{
"constants":{
"collectionTime":1
},
"points":{
"fluctuatingRevenue":[(0, 160), (1, 160), (2, 160), (3, 200), (4, 200), (5, 200), (6,
200), (7, 200), (8, 160), (9, 160), (10, 160), (11, 160), (12,
160), (13, 160), (14, 160), (15, 160), (16, 160), (17, 160), (18,
100), (19, 100), (20, 100), (21, 100), (22, 100), (23, 100), (24,
100)]
}
}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step3_collectionTime1'],
equations=["makingRevenue","collectingRevenue"],
title="Collection Time 1 Month",
x_label="Months",
y_label="€"
)
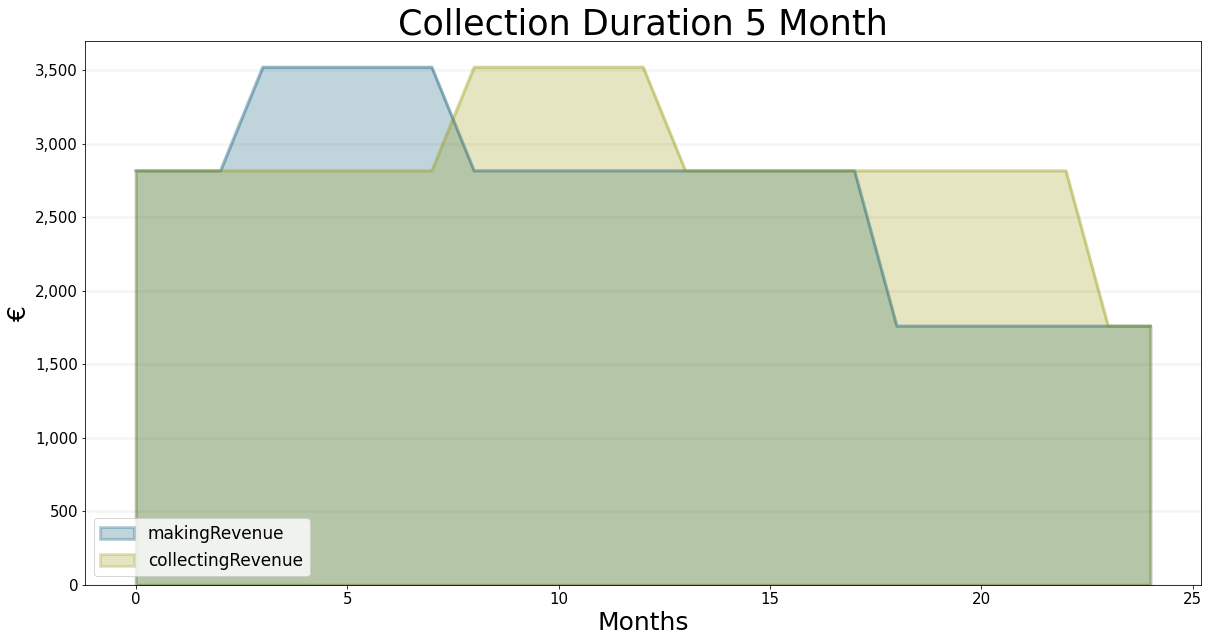
And again for a collection time of 5 months.
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step3_collectionTime5":{
"constants":{
"collectionTime":5
},
"points":{
"fluctuatingRevenue":[(0, 160), (1, 160), (2, 160), (3, 200), (4, 200), (5, 200), (6,
200), (7, 200), (8, 160), (9, 160), (10, 160), (11, 160), (12,
160), (13, 160), (14, 160), (15, 160), (16, 160), (17, 160), (18,
100), (19, 100), (20, 100), (21, 100), (22, 100), (23, 100), (24,
100)]
}
}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step3_collectionTime5'],
equations=["makingRevenue","collectingRevenue"],
title="Collection Duration 5 Month",
x_label="Months",
y_label="€"
)
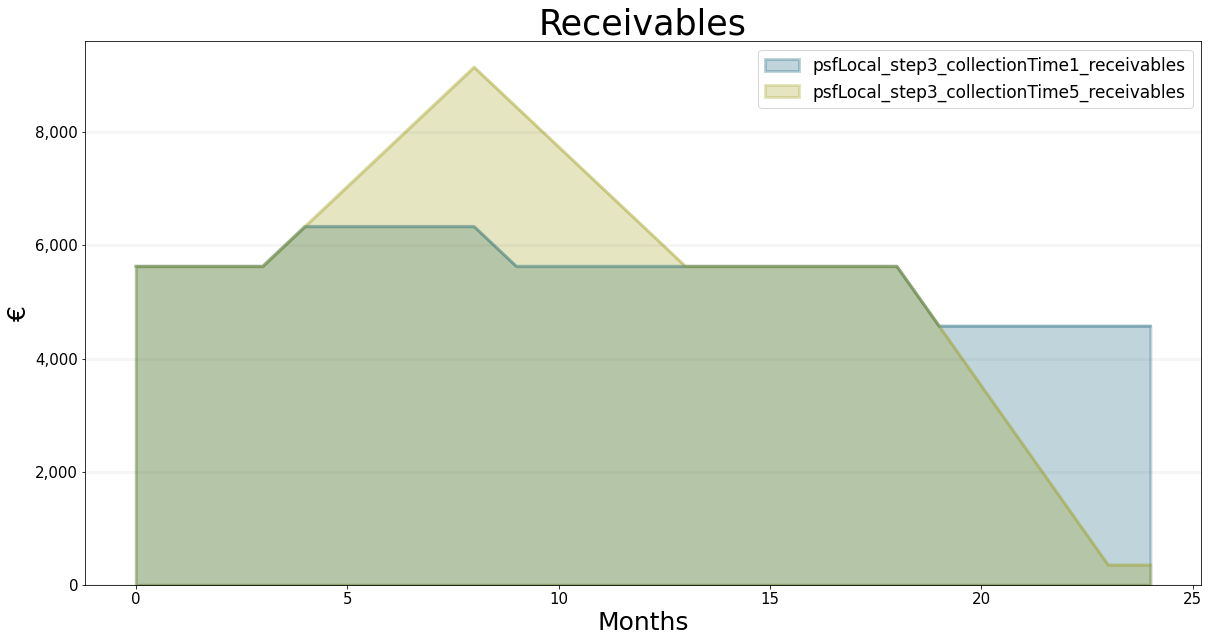
And this is what happens to the receivables in these two scenarios.
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step3_collectionTime1','step3_collectionTime5'],
equations=["receivables"],
title="Receivables",
x_label="Months",
y_label="€"
)
Before we go on to step four, we should take a closer look at the delay funtion - it is used very frequently in System Dynamics and it is important that we understand it properly.
Step 4: Project Delivery Depends on Project Delivery Capacity
In Step 3 we defined revenue as the product of the project delivey fee and the project delivery rate, both were constant in that model. Given the game assumptions we can assume that the delivery fee is constant, but clearly the project delivery rate will depend on how many projects the PSF has acquired and also on how much staff the PSF can assign to project delivery - if no (new) projects are acquired, then the delivery rate will (eventually) be 0 regardless of how much staff the PSF assigns to projects.
On the other hand, if no staff are assigned to project delivery, then the delivery rate will be 0, regardless of the number of projects that have been acquired.
In this step we model the projects as a stock with an initial value of 320 person-months (two months of project backlog, Assumption #15). The outflow is equal to the project delivery rate, which itself is equal to the minimum of projects and the project delivery capacity. For now we assume this capacity is constant at 160 person-months (i.e. 160 project staff delivery one month worth of project work per month).

projects = model.stock("projects")
deliveringProjects = model.flow("deliveringProjects")
projectDeliveryCapacity=model.converter("projectDeliveryCapacity")projects.initial_value = 230.0
projectDeliveryCapacity.equation = 160.0
projects.equation = -deliveringProjects
deliveringProjects.equation = projectDeliveryRate
projectDeliveryRate.equation = sd.min(projects,projectDeliveryCapacity)The plot below shows how the project backlog decreases steadily for the first two months and then remains at 0 - the reason it cuts of at 0 is because we used the MIN-function to constrain the outflow projectDeliveryRate.
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step4":{}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step4'],
equations=["projects"],
title="Projects Base Case"
)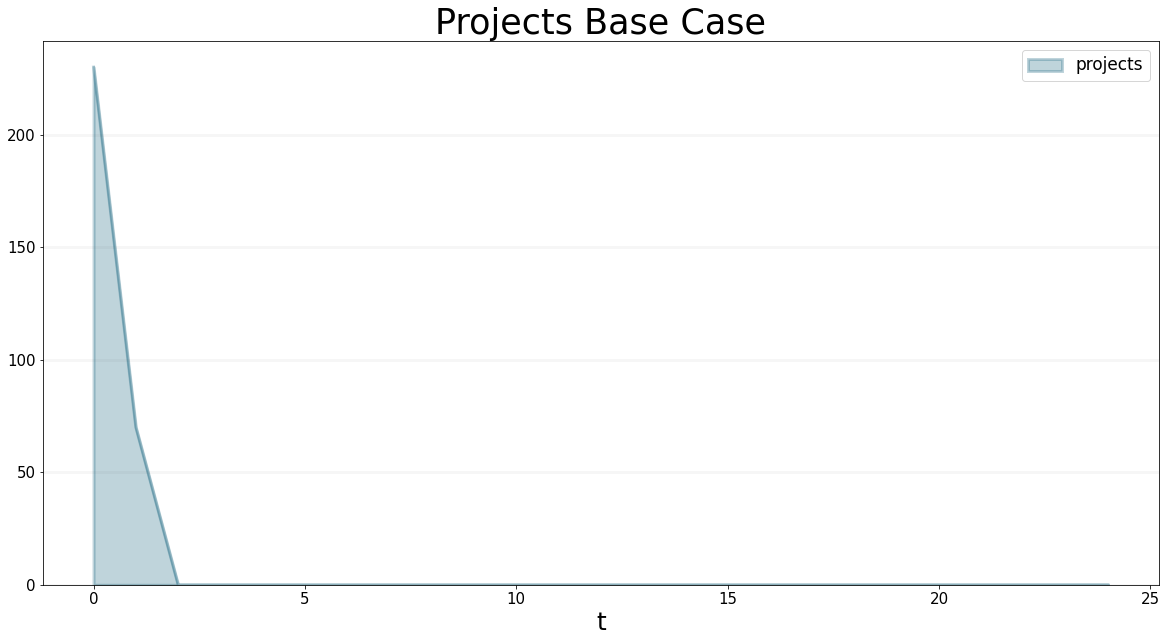
Initially, the delivery capacity is exactly half of the project backlog, so the backlog drops to zero after two months. We can test a closer look at this mechanism if we use different values for the delivery capacity - the graphs below show that as soon as the project backlog drops below the project delivery capacity, the delivery rate is constrained to be equal to the project backlog, before it drops down to zero.
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step4_devCap100":{
"constants":{
"projectDeliveryCapacity":100
}
},
"step4_devCap200":{
"constants":{
"projectDeliveryCapacity":200
}
},
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step4_devCap100','step4_devCap200'],
equations=["projects"],
title="Projects"
)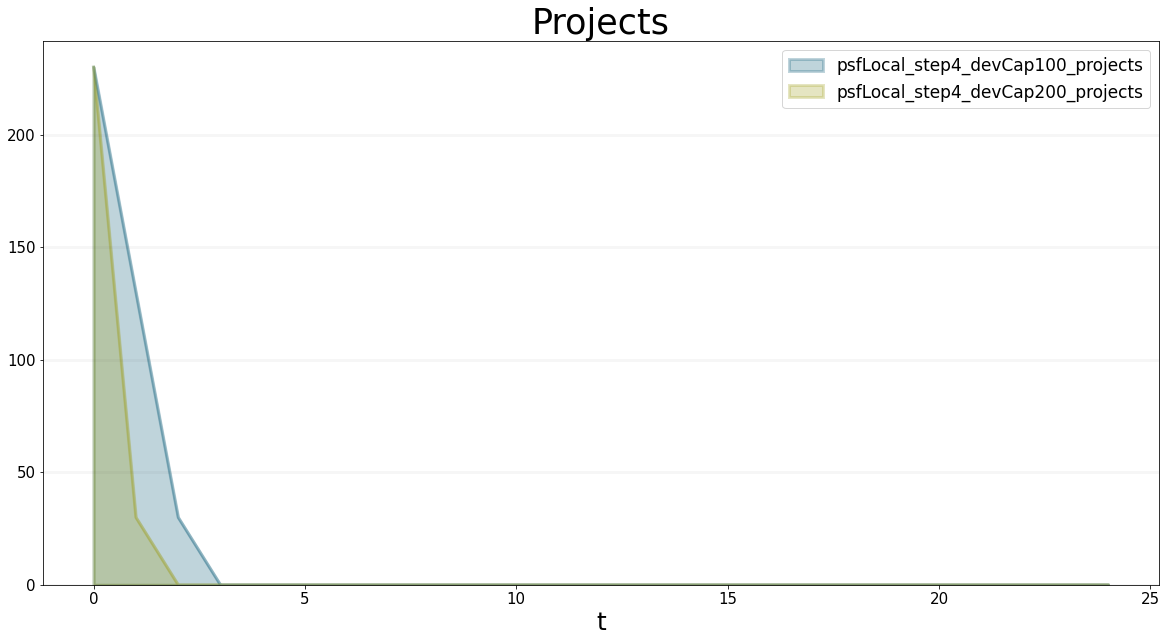
You can see this even better if you take a look at the concrete figures:
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step4_devCap100'],
equations=["projects","projectDeliveryRate"],
title="Projects",
return_df=True
)| projects | projectDeliveryRate | |
|---|---|---|
| t | ||
| 0.0 | 230.0 | 100.0 |
| 1.0 | 130.0 | 100.0 |
| 2.0 | 30.0 | 30.0 |
| 3.0 | 0.0 | 0.0 |
| 4.0 | 0.0 | 0.0 |
| 5.0 | 0.0 | 0.0 |
| 6.0 | 0.0 | 0.0 |
| 7.0 | 0.0 | 0.0 |
| 8.0 | 0.0 | 0.0 |
| 9.0 | 0.0 | 0.0 |
| 10.0 | 0.0 | 0.0 |
| 11.0 | 0.0 | 0.0 |
| 12.0 | 0.0 | 0.0 |
| 13.0 | 0.0 | 0.0 |
| 14.0 | 0.0 | 0.0 |
| 15.0 | 0.0 | 0.0 |
| 16.0 | 0.0 | 0.0 |
| 17.0 | 0.0 | 0.0 |
| 18.0 | 0.0 | 0.0 |
| 19.0 | 0.0 | 0.0 |
| 20.0 | 0.0 | 0.0 |
| 21.0 | 0.0 | 0.0 |
| 22.0 | 0.0 | 0.0 |
| 23.0 | 0.0 | 0.0 |
| 24.0 | 0.0 | 0.0 |
Step 5: Allocating Work Capacity
In our Step 4 model we assumed that the project delivery capacity was constant and equal to 160 - while this value is certainly correct at the beginning of the simulation, it will not be constant throughout the game, because the project delivery capacity depends on the number of professional staff we have and on the percentage of staff assigned to project delivery (or business development, whichever way you look at it).
The diagram below shows how we can model this - given the number of professional staff and the average amount of work done per staff member per month (the “work month”), we can easily calculate the work capacity as the product of these two numbers. The business development capacity is then equal to the work capacity multiplied with the percentage of staff allocated to business development, and the project delivery capacity is then simply the difference between work capacity and business development capacity (because the assumption is that professional staff either work in project delivery or in business development).

workMonth = model.converter("workMonth")
workCapacity = model.converter("workCapacity")
businessDevelopmentCapacity = model.converter("businessDevelopmentCapacity")
businessDevelopmentAllocationPct = model.converter("businessDevelopmentAllocation%")The following equations specify this in detail:
professionalStaff.initial_value = 200.0
workMonth.equation=1.0
workCapacity.equation=professionalStaff*workMonth
businessDevelopmentAllocationPct.equation = 20.0
businessDevelopmentCapacity.equation = workCapacity * businessDevelopmentAllocationPct/100
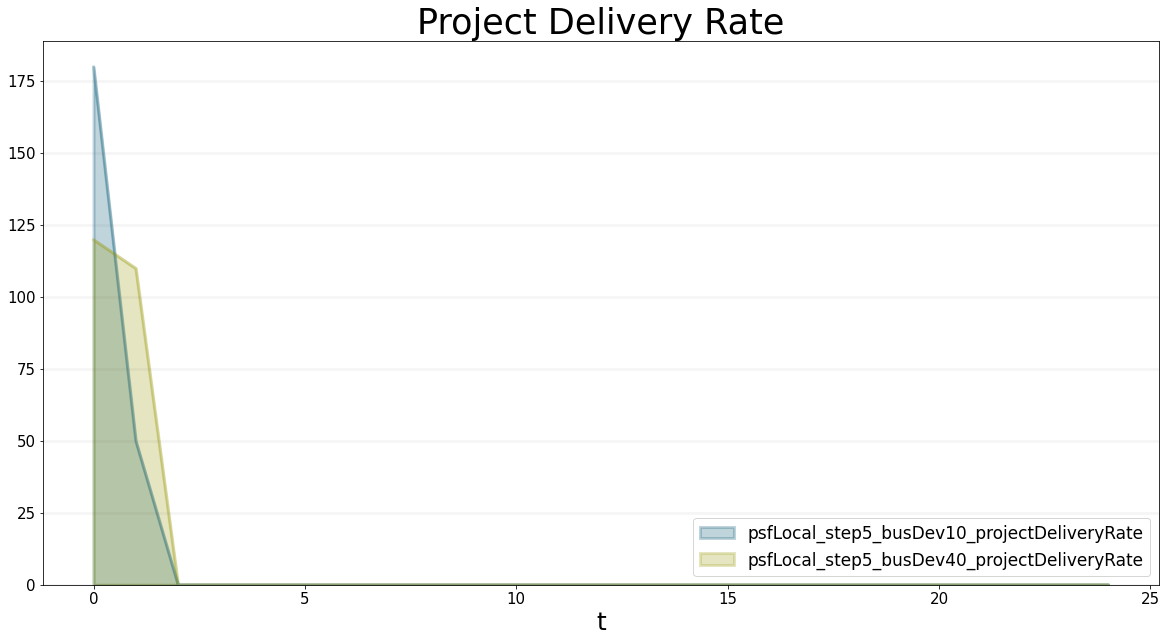
projectDeliveryCapacity.equation = workCapacity-businessDevelopmentCapacityWe can test the model by comparing the project delivery capacity, the project delivery rate and the project backlog for different business development allocations:
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={
"step5_busDev10":{
"constants":{
"businessDevelopmentAllocation%":10
}
},
"step5_busDev40":{
"constants":{
"businessDevelopmentAllocation%":40
}
}
}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step5_busDev10','step5_busDev40'],
equations=["projectDeliveryCapacity"],
title="Project Delivery Capacity"
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step5_busDev10','step5_busDev40'],
equations=["projectDeliveryRate"],
title="Project Delivery Rate"
)
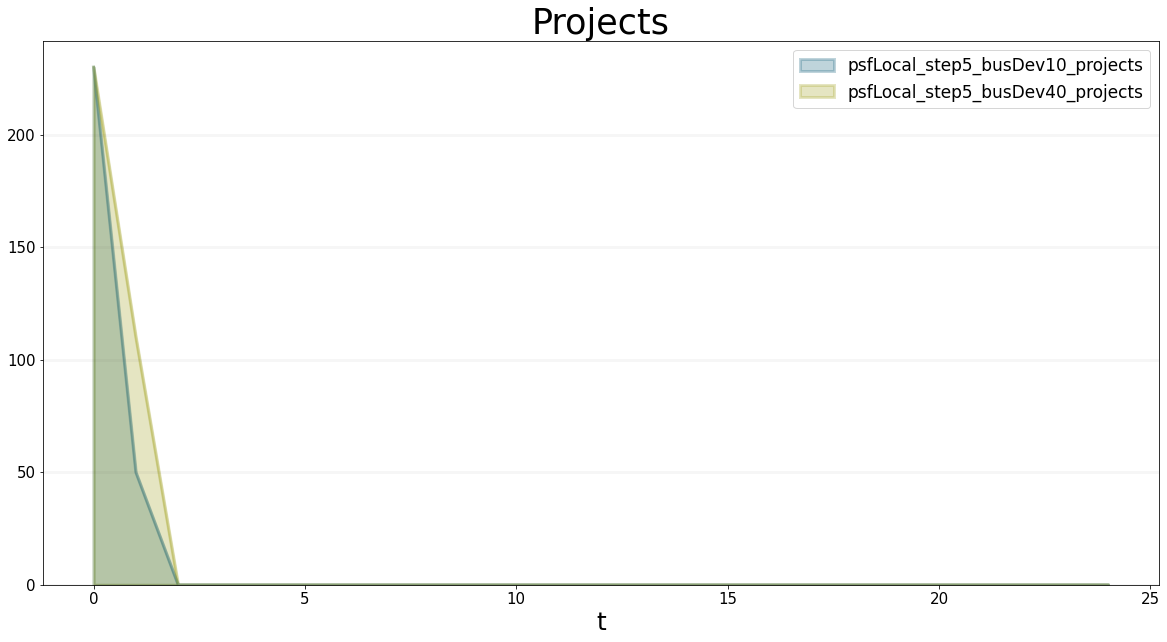
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step5_busDev10','step5_busDev40'],
equations=["projects"],
title="Projects"
)
Step 6: Modeling Project Acquisition
Slowly we are getting there, our model is almost complete now. We have all the stocks in place, but two of them - Projects and Staff - still have no inflows. Let’s take a look at the project acquisition process first.

proposals = model.stock("proposals")
prospectingProjects = model.flow("prospectingProjects")
winningProjects = model.flow("winningProjects")
proposalRate = model.converter("proposalRate")
prospectingEffort = model.converter("prospectingEffort")
projectVolume = model.converter("projectVolume")
projectAcquisitionDuration = model.converter("projectAcquisitionDuration")Taking a look at #3 of our assumptions, we know that it takes 4 months of effort to generade a lead and write a proposal.
prospectingEffort.equation = 4We also know that a project we acquire will have a volume of 16 person months (Assumption #1).
projectVolume.equation = 16In step 5 we introduced a converter that tracks our business development capacity, so we can calculate the rate at which we generate proposals as:
proposalRate.equation = prospectingEffort * projectVolume * businessDevelopmentCapacity
prospectingProjects.equation = proposalRateFrom Assumption #4 we know that it takes six months to turn a proposal into a project – we model this using a delay function:
projectAcquisitionDuration.equation = 6
winningProjects.equation = sd.delay(model,prospectingProjects,projectAcquisitionDuration)Note that all proposals end up being projects, there is no loss - this is because we are assuming that market conditions are perfect (Assumption #5).
How can we test this part of the model?
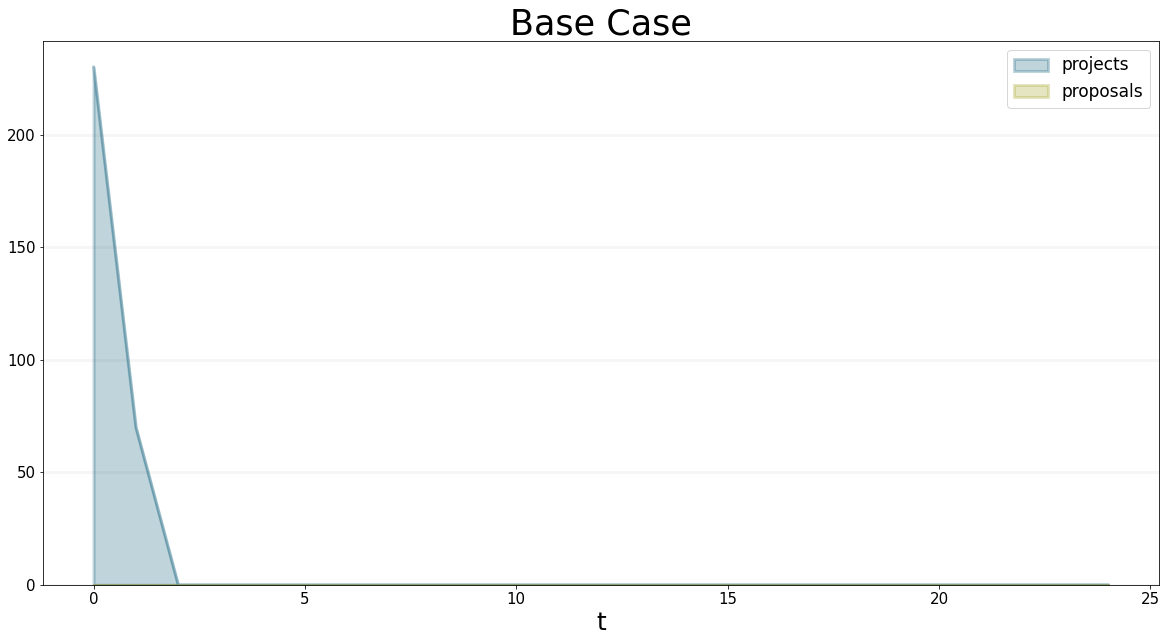
Well in the steady state, we expect the number of proposals in the pipeline to be equal to the number of projects in the project backlog. The following graphs show that this is so:
bptk.register_scenarios(
scenario_manager="psfLocal",
scenarios={"step6":{}}
)bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step6'],
equations=["projects","proposals"],
title="Base Case"
)
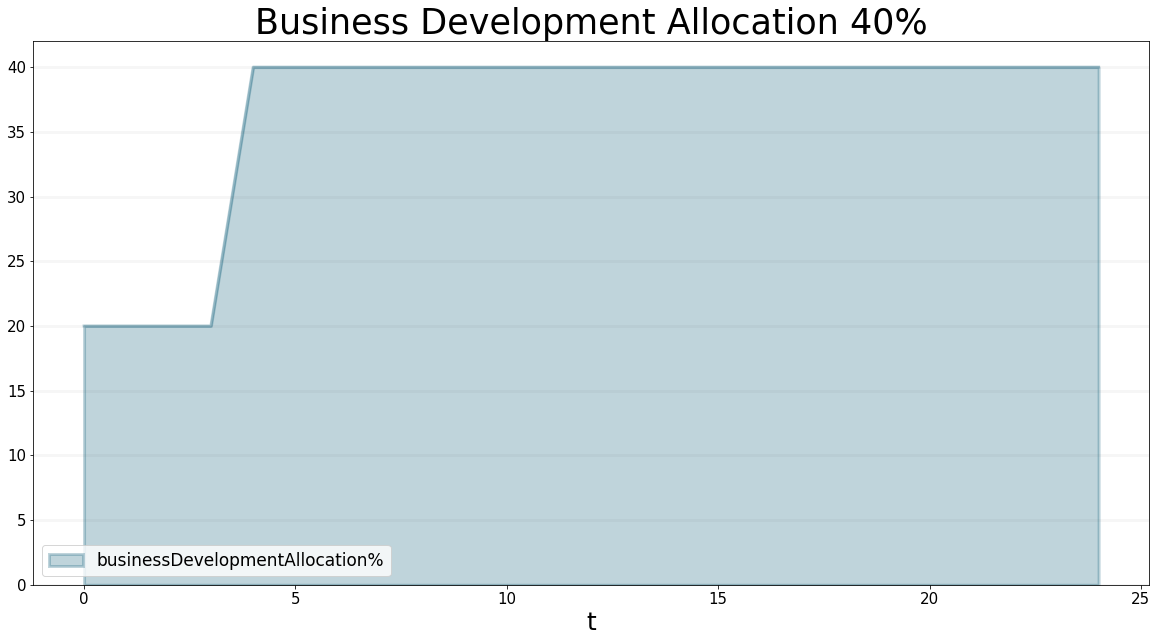
Now let’s see what happens if we increase the percentage of staff allocated to business development to 40% after 3 months - we expect the number of proposals to go up as soon as we do this. Because we can only increase our business development staff by reducing project delivery staff, we would expect the project backlog to rise straight away. We should be generating more proposals now, but because of the acquisition duration, we wouldn’t expect this to have an effect on the project backlog for 6 months - hence there should be a steper increase in the project backlog starting in month 9.
businessDevelopmentAllocationPct.equation=sd.lookup(sd.time(),"businessDevelopmentAllocation%")bptk.register_scenarios(scenario_manager="psfLocal",scenarios={
"step6_base":{
"points":{
"businessDevelopmentAllocation%":[(0, 20), (1, 20), (2, 20), (3, 20), (4, 20), (5, 20), (6,
20), (7, 20), (8, 20), (9, 20), (10, 20), (11, 20), (12,
20), (13, 20), (14, 20), (15, 20), (16, 20), (17, 20), (18,
20), (19, 20), (20, 20), (21, 20), (22, 20), (23, 20), (24,
20)]
}
},
"step6_busDev":{
"points":{
"businessDevelopmentAllocation%":[(0, 20), (1, 20), (2, 20), (3, 20), (4, 40), (5, 40), (6,
40), (7, 40), (8, 40), (9, 40), (10, 40), (11, 40), (12,
40), (13, 40), (14, 40), (15, 40), (16, 40), (17, 40), (18,
40), (19, 40), (20, 40), (21, 40), (22, 40), (23, 40), (24,
40)]
}
}
})bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step6_busDev'],
equations=["businessDevelopmentAllocation%"],
title="Business Development Allocation 40%"
)
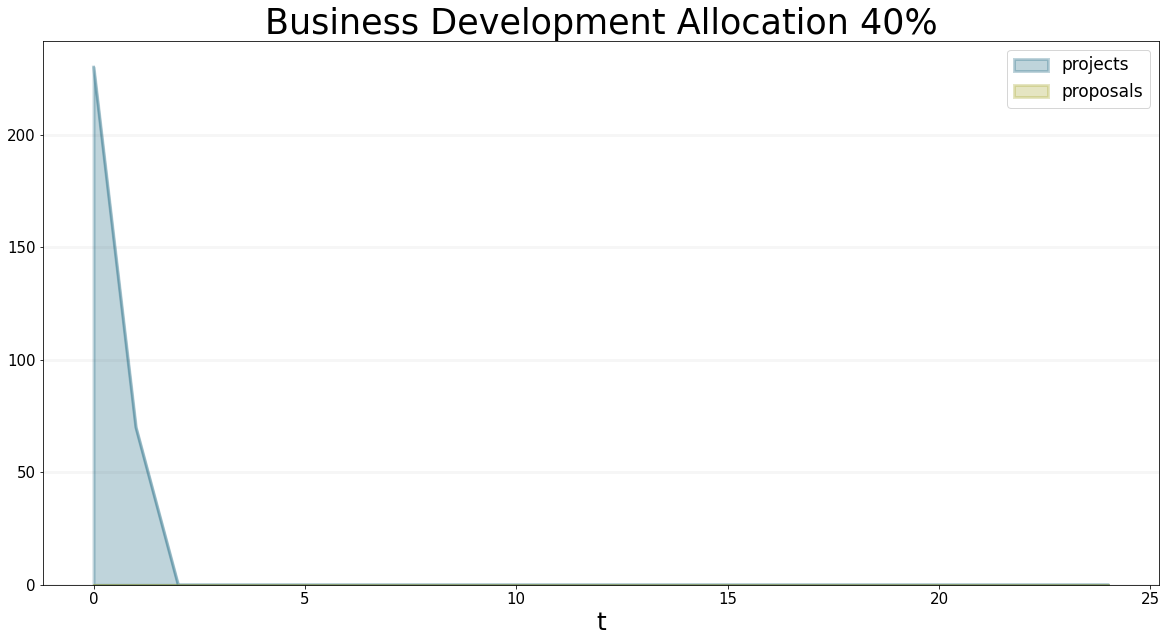
Below I’ve provided both the graphs and the concrete values of the proposals and the project backlog in this scenario - as expected, the number of proposals starts rising as soon as we reallocate staff to business development. The project backlog starts to rise straight away because we have reallocated staff from project delivery to business development - in month 10 (i.e. 6 months after realloacting staff) the first projects are acquired and hence the project backlog starts rising even faster - of course we should have hired some extra project staff by this point to compensate, we can test this in the next step
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step6_busDev'],
equations=["projects","proposals"],
title="Business Development Allocation 40%"
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step6_busDev'],
equations=["projects","proposals"],
title="Business Development Allocation 40%",
return_df=True
)| projects | proposals | |
|---|---|---|
| t | ||
| 0.0 | 230.0 | 0 |
| 1.0 | 70.0 | 0 |
| 2.0 | 0.0 | 0 |
| 3.0 | 0.0 | 0 |
| 4.0 | 0.0 | 0 |
| 5.0 | 0.0 | 0 |
| 6.0 | 0.0 | 0 |
| 7.0 | 0.0 | 0 |
| 8.0 | 0.0 | 0 |
| 9.0 | 0.0 | 0 |
| 10.0 | 0.0 | 0 |
| 11.0 | 0.0 | 0 |
| 12.0 | 0.0 | 0 |
| 13.0 | 0.0 | 0 |
| 14.0 | 0.0 | 0 |
| 15.0 | 0.0 | 0 |
| 16.0 | 0.0 | 0 |
| 17.0 | 0.0 | 0 |
| 18.0 | 0.0 | 0 |
| 19.0 | 0.0 | 0 |
| 20.0 | 0.0 | 0 |
| 21.0 | 0.0 | 0 |
| 22.0 | 0.0 | 0 |
| 23.0 | 0.0 | 0 |
| 24.0 | 0.0 | 0 |
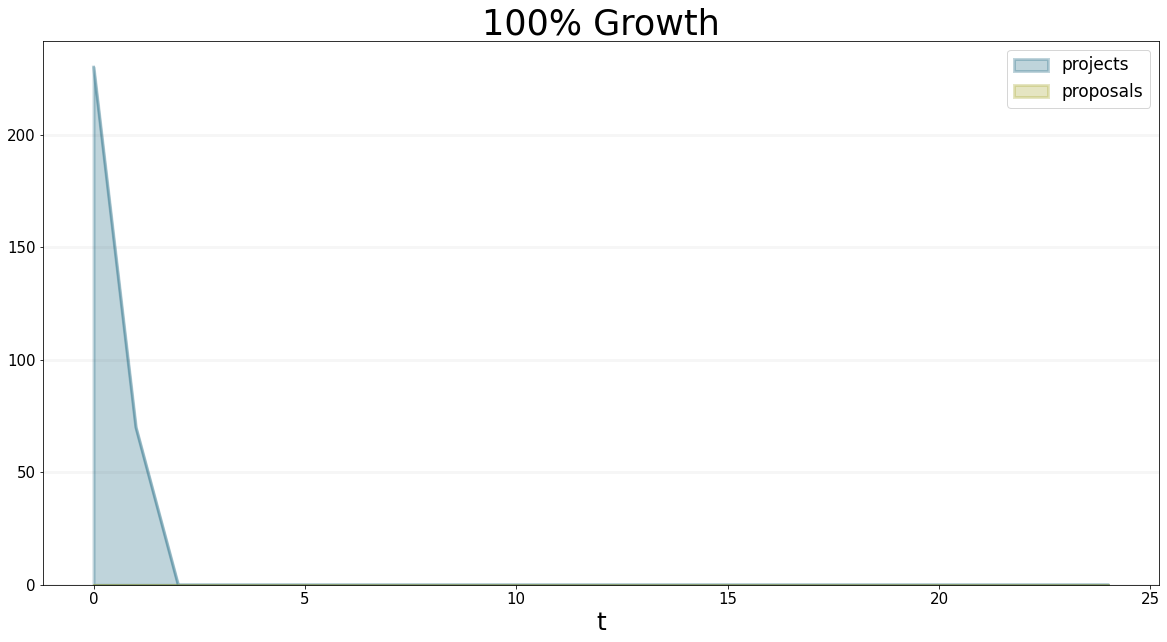
But why does the number of proposals peak at 1280 proposals?
Well if you take a little moment to think about it (I certainly had to) then it becomes obvious - in month 4, we assign 40% of our staff to business development. They immediately start generating proposals at a rate of 0.420016/4=320 project-Months per Month. Every month 160 project-months leave the proposal backlog and enter the project backlog. The delay is 6 months, so in month 10 we expect to have 160*6=960 extra project months in the pipeline. If we add these to the 320 project-months that were already in the stock of propsoals, we arrive at 960+320=1280. At month 10, the number of projects-months leaving the stock of proposals rises to 320, which equals the number coming in. So at this time, the level of proposals becomes steady at 1280.
Below is a graph that shows that the project proposal rate changes from 160 to 320, as expected.
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step6_base','step6_busDev'],
equations=["proposalRate"],
title="Project Proposal Rate"
)
Step 7: Modeling Recruitment
The only aspect of our model that is missing now is staff recruitment - recruitment is zero initially, but setting the recruitment to the right level is part of finding the right game strategy.
We model recruitment as a simple stock and flow structure which involves a delay depending on the hiring duration - the stock and flow diagram and corresponding equations are shown below - we know that the hiring duration is 3 months thanks to assumption #12

staffInRecruitment = model.stock("staffInRecruitment")
hiringStaff = model.flow("hiringStaff")
staffArriving = model.flow("staffArriving")
hiringRate = model.converter("hiringRate")
hiringDuration = model.converter("hiringDuration")staffInRecruitment.initial_value=0.0
staffInRecruitment.equation = hiringStaff-staffArriving
professionalStaff.equation = staffArriving
hiringStaff.equation = hiringRate
staffArriving.equation = sd.delay(model, hiringStaff, hiringDuration)
hiringRate.equation = sd.lookup(sd.time(),"hiringRate")
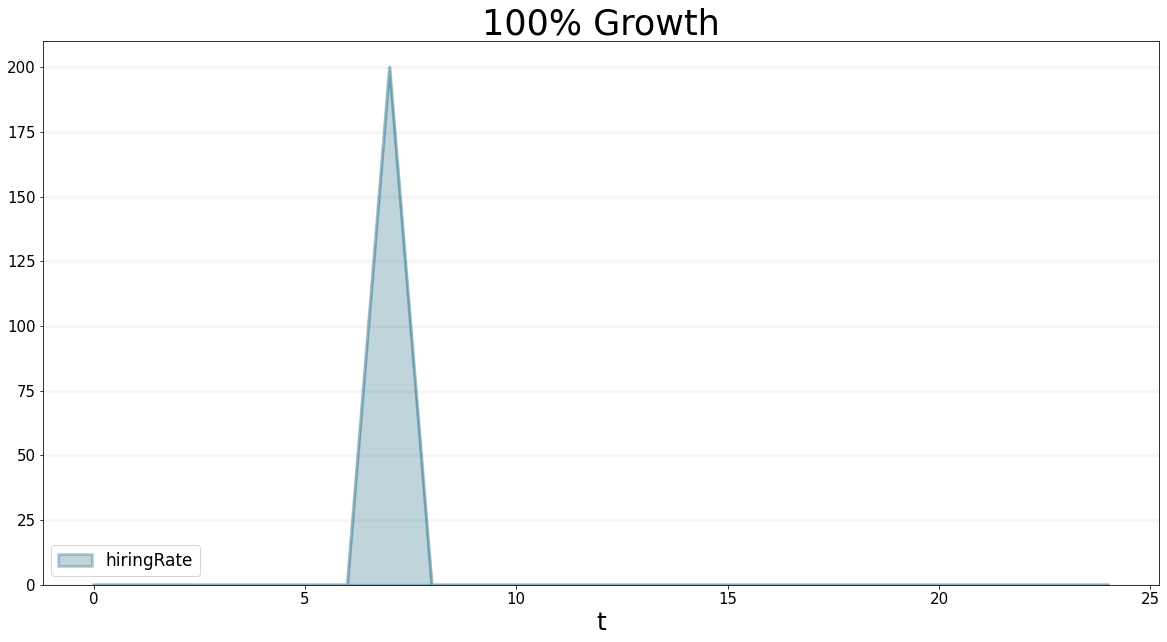
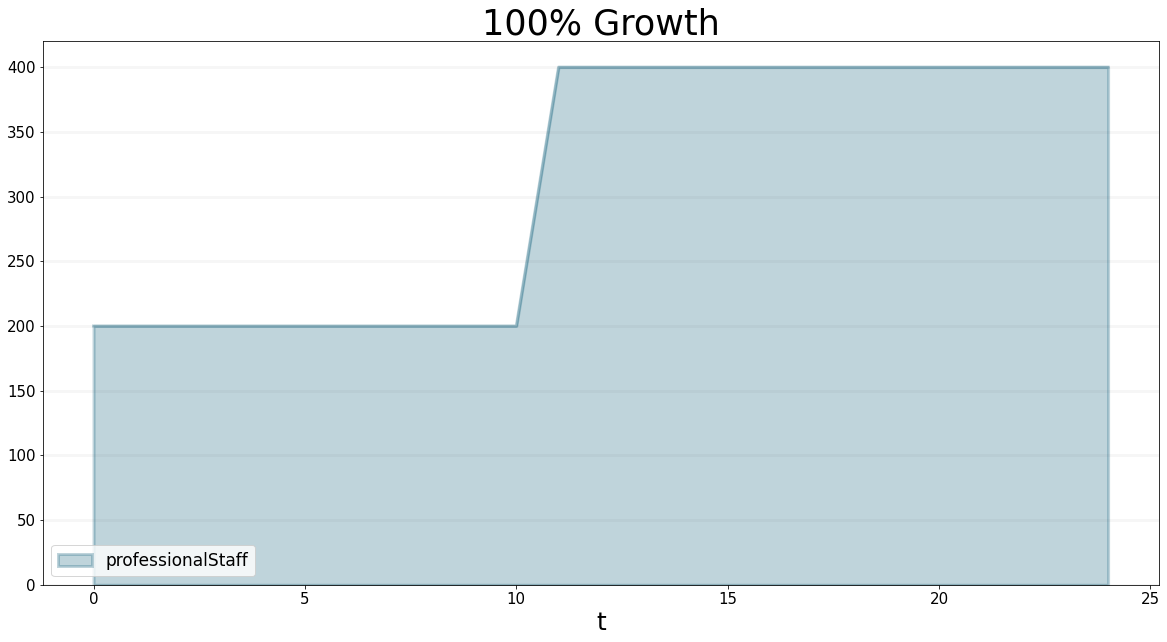
hiringDuration.equation = 3.0We can now continue the scenario we investigated in step 6: in time step 4, we changed the business development allocation to 40%, which led to the project backlog increasing. We also saw that the backlog of proposals leveled out after 10 months, with an outflow of 320 project months per month. In order to deal with so many projects, we need 320 project delivery staff, next to 80 business development staff.
Because hiring actually takes the months, we need to hire them in timestep 7.
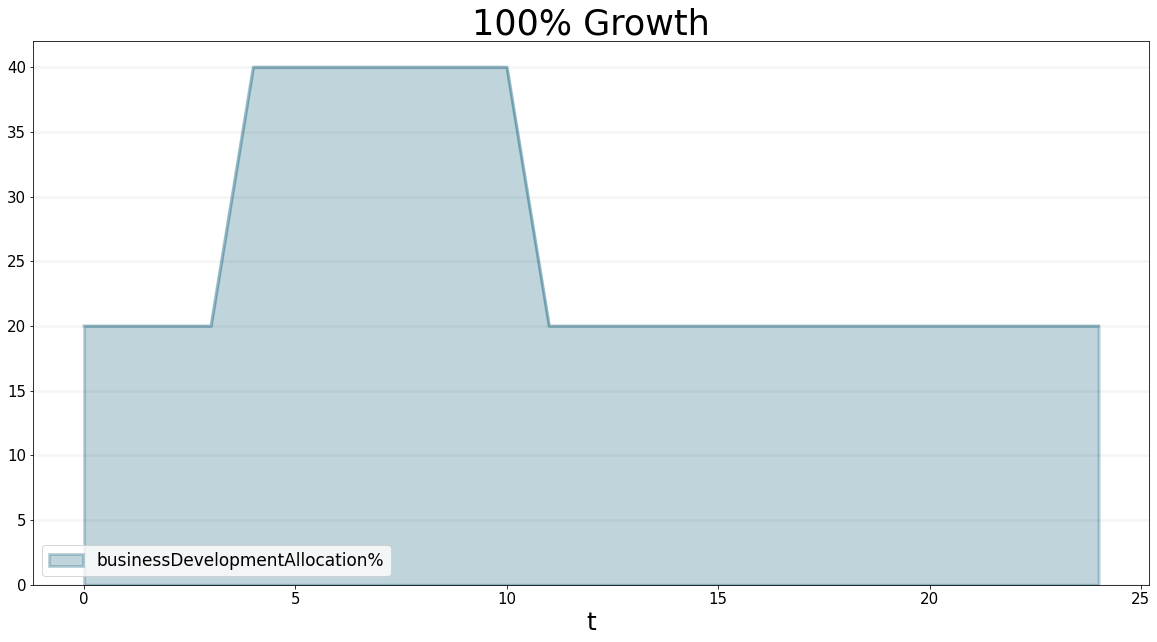
Once they arrive we will need to change the ratio of business development, because now we will have 80 business developers and 400 staff total, so the percentage will be back to 20%.
All in all this leads to a 100 % growth scenario. Let’ s check to see how our model behaves.
bptk.register_scenarios(scenario_manager="psfLocal",scenarios={
"step7_base":{
"points":{
"businessDevelopmentAllocation%":[(0, 20), (1, 20), (2, 20), (3, 20), (4, 20), (5, 20), (6,
20), (7, 20), (8, 20), (9, 20), (10, 20), (11, 20), (12,
20), (13, 20), (14, 20), (15, 20), (16, 20), (17, 20), (18,
20), (19, 20), (20, 20), (21, 20), (22, 20), (23, 20), (24,
20)],
"hiringRate":[(0, 0), (1, 0), (2, 0), (3, 0), (4, 0), (5, 0), (6,
0), (7, 0), (8, 0), (9, 0), (10, 0), (11, 0), (12,
0), (13, 0), (14, 0), (15, 0), (16, 0), (17, 0), (18,
0), (19, 0), (20, 0), (21, 0), (22, 0), (23, 0), (24,
0)]
}
},
"step7_busDev":{
"points":{
"businessDevelopmentAllocation%":[(0, 20), (1, 20), (2, 20), (3, 20), (4, 40), (5, 40), (6,
40), (7, 40), (8, 40), (9, 40), (10, 40), (11, 20), (12,
20), (13, 20), (14, 20), (15, 20), (16, 20), (17, 20), (18,
20), (19, 20), (20, 20), (21, 20), (22, 20), (23, 20), (24,
20)],
"hiringRate":[(0, 0), (1, 0), (2, 0), (3, 0), (4, 0), (5, 0), (6,
0), (7, 200), (8, 0), (9, 0), (10, 0), (11, 0), (12,
0), (13, 0), (14, 0), (15, 0), (16, 0), (17, 0), (18,
0), (19, 0), (20, 0), (21, 0), (22, 0), (23, 0), (24,
0)]
}
}
})bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step7_busDev'],
equations=["hiringRate"],
title="100% Growth"
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step7_busDev'],
equations=["projects","proposals"],
title="100% Growth"
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step7_busDev'],
equations=["professionalStaff"],
title="100% Growth"
)
bptk.plot_scenarios(
scenario_managers=["psfLocal"],
scenarios=['step7_busDev'],
equations=["businessDevelopmentAllocation%"],
title="100% Growth"
)
Great, we now have a complete model. We shoud now perform some sanity checks to see whether it is working correctly. Before we do that, we ought to make sure that we have incorporated all assumptions in the list. When building models we mostly keep an excel sheet containg all requirements and assumptions regarding the model and any issues that arise along the way. That way we can make sure we don’t forget anything.
The table below shows which assumption is covered in which model step.

Performing Initial Sanity Checks
Great, we now have a complete model. But before we start experimenting with growth strategies, we ought to ensure that the model behaves as expected. For this we have extracted the model we built in the preceding sections into a separate model file. We will use this version of the model to perform sanity checks and also in the subsequent notebooks to explore growth strategies.
import BPTK_Py
bptk = BPTK_Py.bptk()bptk.plot_scenarios(
scenario_managers=["psf"],
scenarios=['base'],
equations=["kpi.projectBacklog"],
title="Relative Project Backlog",
x_label="Months",
y_label="Months of Coverage"
)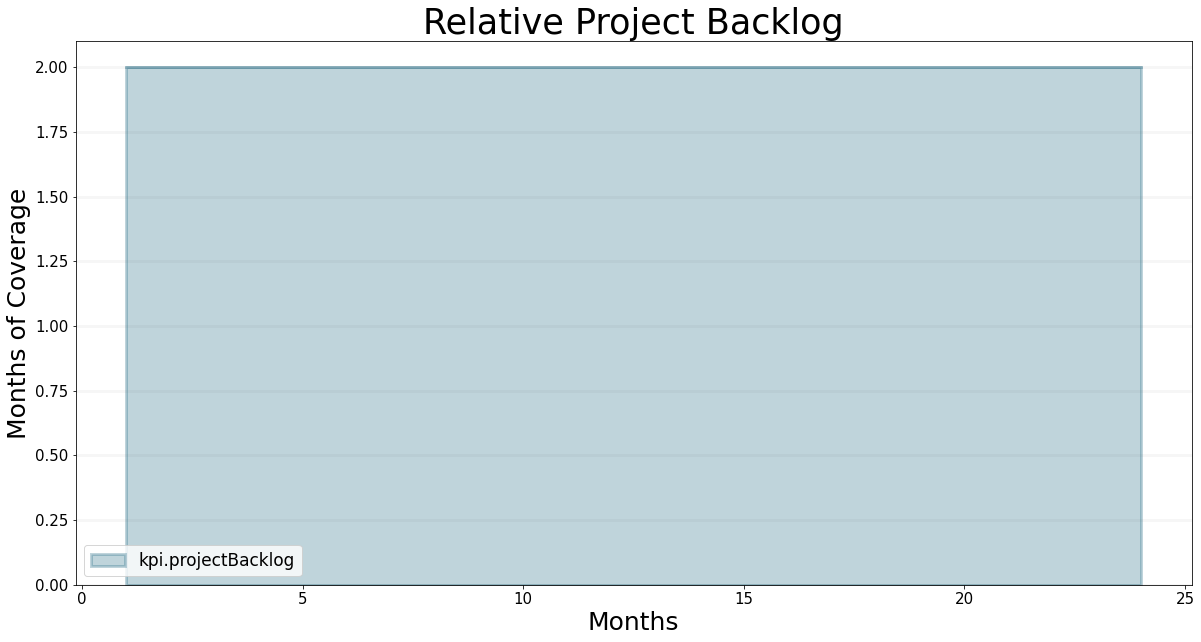
Let’s do a few quick calculations to make sure we understand the underlying assumptions… the company has 200 professional staff members, 20% of which are assigned to business development. This means that 160 persons are continuously working on projects. The initial project backlog has 320 months in absolute terms, i.e. the backlog relative to the number of project staff is 2 months into the future.
df_psf_base=bptk.plot_scenarios(
scenario_managers=["psf"],
scenarios=['base'],
equations=["cash.cash","revenue.revenue","cost.staffCost","cost.overheadCost"],
title="Base Case",
x_label="Months",
y_label="k€",
return_df=True
)totalRevenue=df_psf_base["revenue.revenue"].iloc[0]*1000
staffCost=df_psf_base["cost.staffCost"].iloc[0]*1000
overheadCost=df_psf_base["cost.overheadCost"].iloc[0]*1000
totalCost=staffCost+overheadCost
cashFlow=totalRevenue-totalCost
initialCash=1000000
cash2Years=23*cashFlow+initialCashRevenue Check: Initially, the PSF is fully booked and working at a rate of 160 person months per month, so the company is making EUR 160 * 17600 = 2,816,000 per month of revenue from projects.
The cost side is a little more intricate: each staff member costs EUR 80000/12 = 6666 on salaries and an extra EUR 1000 workplace cost, i.e. EUR 7666. At 200 persons in the company, this sums to EUR 1533333 in staff cost.We also have overhead cost of EUR 306,000 per month, so the total cost is at EUR 1,839,333.
Putting all these figures together leads to a cash inflow of EUR 976667 per month.I’ ve summarised these figures in the table below:
import pandas as pd
data_psf_base = [["Revenue", totalRevenue]
, ["Staff Cost",staffCost]
, ["Overhead Cost", overheadCost]
, ["Total Cost", totalCost]
, ["Cash Flow", cashFlow]]
df_psf_base_total = pd.DataFrame(data_psf_base, columns = ["Position", "Value"])
df_psf_base_total.set_index("Position").astype(int)| Value | |
|---|---|
| Position | |
| Revenue | 2816000 |
| Staff Cost | 1533333 |
| Overhead Cost | 306000 |
| Total Cost | 1839333 |
| Cash Flow | 976666 |
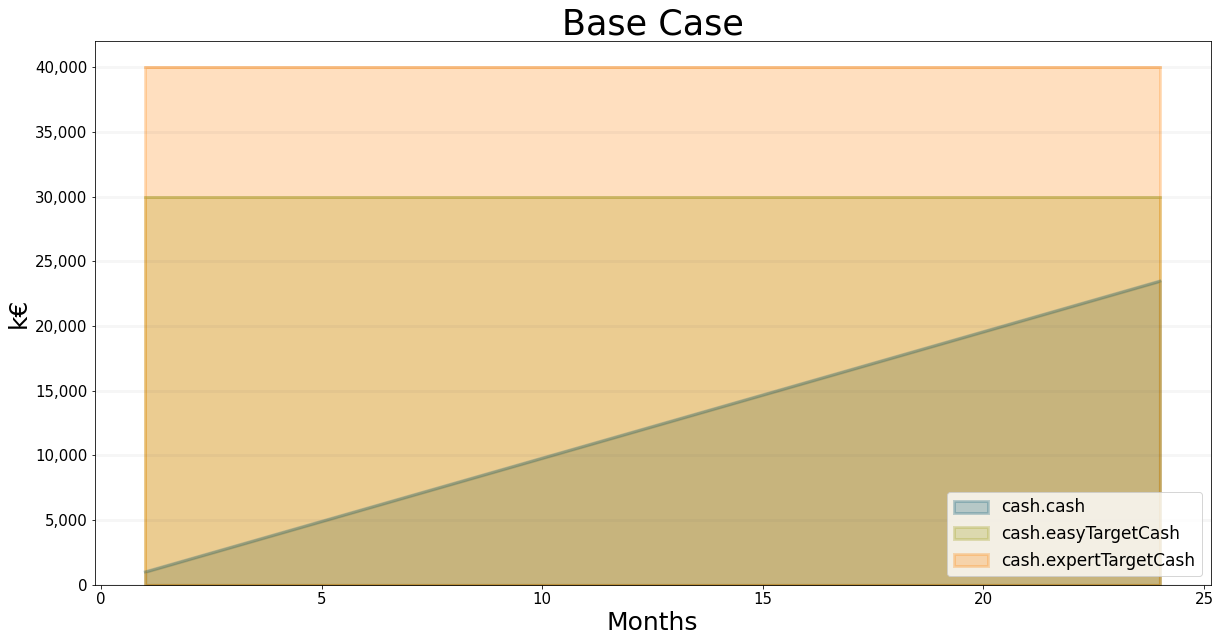
Note that these are monthly figures - so, if these figures remain stable, then after 2 years, at the beginning of month 24, the company will have cash equal to the initial EUR 1 Mio. plus 23*976667 which amounts to EUR 23.463 Mio.
bptk.plot_scenarios(
scenario_managers=["psf"],
scenarios=['base'],
equations=["cash.cash","cash.easyTargetCash","cash.expertTargetCash"],
title="Base Case",
x_label="Months",
y_label="k€"
)
bptk.plot_scenarios(
scenario_managers=["psf"],
scenarios=['base'],
equations=["cash.cash"],
series_names={
"mypsfg_base_cash.cash":"Cash"
},
return_df=True
)| cash.cash | |
|---|---|
| t | |
| 1.0 | 1000.000000 |
| 2.0 | 1976.666667 |
| 3.0 | 2953.333333 |
| 4.0 | 3930.000000 |
| 5.0 | 4906.666667 |
| 6.0 | 5883.333333 |
| 7.0 | 6860.000000 |
| 8.0 | 7836.666667 |
| 9.0 | 8813.333333 |
| 10.0 | 9790.000000 |
| 11.0 | 10766.666667 |
| 12.0 | 11743.333333 |
| 13.0 | 12720.000000 |
| 14.0 | 13696.666667 |
| 15.0 | 14673.333333 |
| 16.0 | 15650.000000 |
| 17.0 | 16626.666667 |
| 18.0 | 17603.333333 |
| 19.0 | 18580.000000 |
| 20.0 | 19556.666667 |
| 21.0 | 20533.333333 |
| 22.0 | 21510.000000 |
| 23.0 | 22486.666667 |
| 24.0 | 23463.333333 |
Fantastic, our model is complete (i.e. it covers all assumptions) and it seems to be behaving as expected. Now you can use it to follow along the discussion in the next chapter. Make sure you can reproduce the values in each step.